
How to extract text from PDF files with python?

Though it is the age of large language models (LLMs) and wide-ranging applications, the importance of simple text is still more remarkable. We share many documents, from web articles to blog posts to simple PDFs. Developing a systematic way to extract their information will help us utilize this vast textual data better. For this task, we are going to use Python.
In this blog, we will discuss how we can extract text from PDF files using Python language. Before you get started, we should know that there are three popular types of PDF files, as mentioned:
Programmatically generated PDFs created on a computer using software like Adobe Acrobat or W3C technologies like HTML, CSS, and Javascript. It has images, text, and links, all searchable and accessible to edit.
Traditional scanned documents are created from non-electronic mediums through a scanner machine or a mobile app. It has nothing more than a collection of images in a PDF file.
Scanned documents with OCR where Optical Character Recognition (OCR) software is employed to scan the document. OCR identifies the text within each image in the file, converting it into searchable and editable text.
Here, we will create a process that considers all these cases and takes the most out of information-rich PDFs. Let’s now get started!
How do you extract text from PDF files with Python?
Before extracting text from the PDF, it is essential to analyze the layout of the PDF. On that basis, we will use an appropriate method for extracting text from the PDF file. The output will be a Python dictionary containing information extracted for each PDF file page.
The dictionary will present the document's page number with its corresponding value with a key. You can access the following:
- Text extracted per text block of the corpus from the images on the page and from tables (in a structured format)
- Format of the text in each text block (font family and size)
- Complete the text content of the page
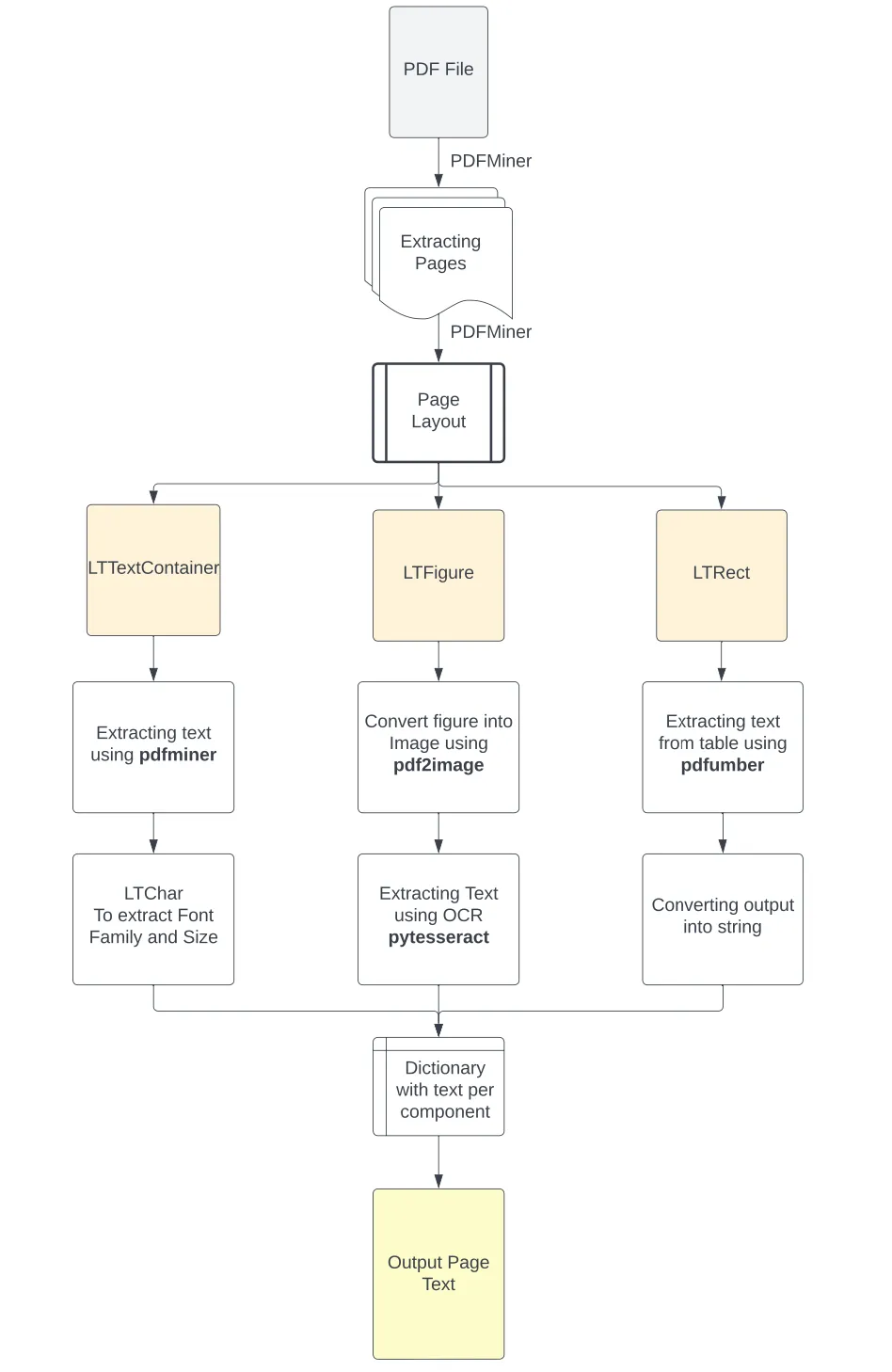
Here is a flow chart representation to understand things better:
First, we should proceed with the installation of the necessary libraries. Our blog considers Python 3.10 or above installed on your machine. Let’s start installing!
Installing Python Libraries
PyPDF2 helps you read the PDF file from the repository path. Run this command for it - pip install PyPDF2
Pdfminer works for layout analysis and extracts text and format from the PDF. Run this command for it - pip install pdfminer.six
Key tip: The .six version of the library is the one that supports Python 3.
Pdfplumber identifies tables in a PDF page and extracts the information from them. Run this command for it - pip install pdfplumber
Pdf2image converts the cropped PDF image to a PNG image. Run this command for it - pip install pdf2image
PIL to read the PNG image. Run this command for it - pip install Pillow
Pytesseract extracts the text from the images using OCR technology. However, to use OCR technology, you must first Google Tesseract OCR. Add their executable paths to Environment Variables on your computer when downloaded and installed. You directly include their paths in the Python script with the following commands:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseracpip install pytesseract
Finally, we will import all the libraries at the beginning of our script:
import PyPDF2from pdfminer.high_level import extract_pages, extract_textfrom pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigureimport pdfplumberfrom PIL import Imagefrom pdf2image import convert_from_pathimport pytesseract import os
The script will read the PDF, analyze the PDF layout, extract text from tables in PDF, extract the images from the PDFs, perform OCR to extract text from images and remove the additional created files.
Explanation of the Flowchart:
PDF files inherently lack structured information, rather than understanding only the individual characters of the text with respect to their position on the page. For the preliminary analysis, we used the PDFMiner Python library to reconstruct the page's content into its individual characters and their position in the file.
To achieve that, the library:
PDFMiner Python library separates the individual pages from the PDF file using the high-level function extract_pages(). It then converts them into LTPage objects.
Then, for each LTPage object, it iterates from each element (top to bottom) to check the appropriate component as either:
- LTFigure (area of the PDF with figure/images) that has been embedded as another PDF document on the page.
- LTTextContainer (a group of text lines in a rectangular area) is analyzed further into a list of LTTextLine objects, representing a list of LTChar objects that store the single text characters along with their metadata.
- LTRect represents a 2-dimensional rectangle that can create tables in an LTPage object.
Therefore, based on this reconstruction of the page and the classification of its elements, we can apply the appropriate function to better extract the information. Let’s now create the functions needed to extract the text from each component.
Function to Extract Text from PDF
To extract text from the PDF, run the following command:
# Create a function to extract textdef text_extraction(element): line_text = element.get_text() line_formats = [] for text_line in element: if isinstance(text_line, LTTextContainer): for character in text_line: if isinstance(character, LTChar): line_formats.append(character.fontname) line_formats.append(character.size) format_per_line = list(set(line_formats)) return (line_text, format_per_line)
Explanation of the Code:
Here, we used the get_text() method of the LTTextContainer element. It extracts text from a text container and retrieves all the characters that make up the words within the specific corpus box. It stores the output in a list of text data.
Now, we iterate through the LTTextContainer object to identify this text’s format. Each iteration creates a new LTTextLine object that represents a line of text in this chunk of corpus.
We examine whether the nested line element contains text, and for that, we pass it in a loop- If it passes the loop, we access each individual character element as LTChar. Here, LTChar contains the metadata for that character. From this metadata, we extract the following:
- The font family of the characters
- The font size for the character
To facilitate further analysis, we capture the unique values for all characters and store them in the appropriate list.
Function to Extract Text from Images
This part deals with the text in the image part of the PDF. To extract text from the images, run the following command:
# First, we write a function to crop the image elements from the respective PDFdef crop_image(element, pageObj): [image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1] pageObj.mediabox.lower_left = (image_left, image_bottom) pageObj.mediabox.upper_right = (image_right, image_top) cropped_pdf_writer = PyPDF2.PdfWriter() cropped_pdf_writer.add_page(pageObj)
with open('cropped_image.pdf', 'wb') as cropped_pdf_file: cropped_pdf_writer.write(cropped_pdf_file)def convert_to_images(input_file,): images = convert_from_path(input_file) image = images[0] output_file = "PDF_image.png" image.save(output_file, "PNG")def image_to_text(image_path): img = Image.open(image_path) text = pytesseract.image_to_string(img) return text
Explanation of the Code:
Here, we followed the following process:
- We used the metadata from the LTFigure object detected from PDFMiner to crop the image box. It utilizes its coordinates in the page layout. We save it as a new PDF (using the PyPDF2 library).
- Next, With the convert_from_file() function from the pdf2image library, we converted all PDF files in the directory into a list of images and saved them in PNG format.
- Finally, we read image files in our script using the Image package of the PIL module and implement the image_to_string() function of pytesseract to extract text from the images using the tesseract OCR engine.
The process returns the text from the images, which we then save in a third list within the output dictionary.
Function to Extract Text from Tables
Here, we will extract text from tables (logically structured) on a PDF page. While extracting text from tables, we must consider the information's granularity and the relationships between data points in a table.
We are using the pdfplumber library for this function. Firstly, because it is built on pdfminer.six, which we used in our preliminary analysis, it contains similar objects. Also, its approach to table detection is based on line elements along with their intersections. Hence, it extracts just the content inside the cell, and then when we have the contents of a table, we format it in a table-like string and store it in the appropriate list.
# Code to extract tables from the pagedef extract_table(pdf_path, page_num, table_num): pdf = pdfplumber.open(pdf_path) table_page = pdf.pages[page_num] table = table_page.extract_tables()[table_num] return tabledef table_converter(table): table_string = '' for row_num in range(len(table)): row = table[row_num] cleaned_row = [item.replace('\n', ' ') if item isn’t None, '\n' in item else 'None' if item= None else item for item in row] table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n') table_string = table_string[:-1] return table_string
Explanation of the code:
Here, we have created two functions, that is:
- extract_table()
- table_converter()
In the extract_table() function, we have code for the follow following steps:
Open the pdf file-> Find the examined page-> Extract the appropriate table-> Output it in a list of nested lists representing each table row.
In the table_converter() function, we have code for the follow following steps:
Convert the table into the appropriate format-> Iterate in each nested list-> Remove the line breaker from the wrapped texts-> Convert the table into a string.
The process gives you a string of text that will present the content of the table, and the data in it won’t lose any granularity.
Complete Code- Sum Up of the Three
Now, it is time to sum up and get our code running! Here is how we add them all up to a fully functional code.
# To find the PDF pathpdf_path = 'OFFER 3.pdf'
# to create a PDF file objectpdfFileObj = open(pdf_path, 'rb')# to create a PDF reader objectpdfReaded = PyPDF2.PdfReader(pdfFileObj)
# To create the dictionary to extract text from each imagetext_per_page = {}#extract the pages from the PDFfor pagenum, page in enumerate(extract_pages(pdf_path)): # Initialize the variables needed for extraction pageObj = pdfReaded.pages[pagenum] page_text = [] line_format = [] text_from_images = [] text_from_tables = [] page_content = [] # To initialize the number of the examined tables table_num = 0 first_element= True table_extraction_flag= False # To open the pdf file pdf = pdfplumber.open(pdf_path) # To find the examined page page_tables = pdf.pages[pagenum] # To find the number of tables on the page tables = page_tables.find_tables()
# To find all the elements page_elements = [(element.y1, element) for element in page._objs] # To sort all the elements as they appear in the page page_elements.sort(key=lambda a: a[0], reverse=True)
# To find the elements that composed a page for i,component in enumerate(page_elements): # To extract the position of the top side of the element in the PDF pos= component[0] # To extract the element of the page layout element = component[1] # To check if the element is a text element if isinstance(element, LTTextContainer): # To check if the text appeared in a table if table_extraction_flag == False: # Extract format for each text element (line_text, format_per_line) = text_extraction(element) # To append the text of each line to the page text page_text.append(line_text) # To append the format for each line containing text line_format.append(format_per_line) page_content.append(line_text) else: # Here, pass the text that appeared in a table pass
# To check the elements for images if isinstance(element, LTFigure): # To crop the image from the PDF crop_image(element, pageObj) # To convert the cropped pdf to an image convert_to_images('cropped_image.pdf') # Extract text from image portion image_text = image_to_text('PDF_image.png') text_from_images.append(image_text) page_content.append(image_text) # To add a placeholder in the text and format lists page_text.append('image') line_format.append('image')
# To check the elements for tables if isinstance(element, LTRect): # If rectangular element is first if first_element == True and (table_num+1) <= len(tables): # Check the bounding box of the table lower_side = page.bbox[3] - tables[table_num].bbox[3] upper_side = element.y1 # To extract the information from the table table = extract_table(pdf_path, pagenum, table_num) # Convert the table information in string (structured) table_string = table_converter(table) # Now, append the table string into a list text_from_tables.append(table_string) page_content.append(table_string) # Here, we set the flag as True to avoid the content again table_extraction_flag = True # To make it another element first_element = False # To add a placeholder in the text and format lists page_text.append('table') line_format.append('table')
# To check (already) extracted the tables from the page if element.y0 >= lower_side and element.y1 <= upper_side: pass elif not isinstance(page_elements[i+1][1], LTRect): table_extraction_flag = False first_element = True table_num+=1
# To create the key of the dictionary dctkey = 'Page_'+str(pagenum) # Add the list of list as the value of the page key text_per_page[dctkey]= [page_text, line_format, text_from_images,text_from_tables, page_content]
# Close pdf file objectpdfFileObj.close()
# Delete the additional files createdos.remove('cropped_image.pdf')os.remove('PDF_image.png')
# Display the text of the pageresult = ''.join(text_per_page['Page_0'][4])print(result)
Explanation of the code:
The script above will run for the following steps:
Import needful libraries-> Open PDF with pyPDF2 library-> Extract each page of the PDF for the following:
- Examine any tables and create a list of them using pdfplumner.
- Find all elements nested in the page and sort them.
Next, for each element:
- Check if it is a text container, does not appear in a table element, and uses the text_extraction() function. It extracts the text along with its format, else passes this text.
- Checks if it is an image, uses the crop_image() function to crop it, and converts it into an image file with convert_to_images() function. Extracts text from it using OCR using image_to_text() function.
- Check if it is a rectangular element; if yes, examine if the first rect is part of a page’s table. If yes, does the following:
- Find the bounding box of the table with the text_extraction() function.
- Extract table’s content and convert it into a string.
- Add a boolean parameter to extract text from the Table.
- Repeat the process until the last LTRect falls into the bounding box of the table and the next element in the layout is not a rectangular object.
The outputs of the process will be stored in 5 lists per iteration will be stored under the key in a dictionary as follows:
- page_text: list has all the text coming from text containers in the PDF
- line_format: list has all the formats of the texts extracted above
- text_from_images: list has all the texts extracted from images
- text_from_tables: list has all the table-like string with the contents of tables
- page_content: list has all the text rendered on the page in a list of elements
Next, we close the PDF file and delete all the additional files created during the process.
Finally, we display the content of the page. It is done by joining the elements of the page_content list.
Summary
This guide discussed a complete process to extract textual information from tables, images, and plain text from a PDF file. We have chosen one of the inclusive approaches to extract text from PDF. The process uses the best characteristics of many libraries. Also, it makes the process resilient to various types of PDFs.